Storage Indexing
데이터베이스는 데이터를 효율적으로 저장하고 처리하는 시스템으로, 활용 목적에 따라 OLTP와 OLAP으로 나뉩니다. 또한, 인덱스는 데이터 검색 속도를 높이기 위한 핵심 기술로, 이를 효과적으로 활용하면 데이터베이스의 성능을 최적화할 수 있습니다.
OLTP
OLTP(Online Transaction Processing)는 실시간으로 데이터를 처리하는 트랜잭션 중심의 시스템입니다. 빠른 응답 시간과 데이터 일관성을 유지하는 것이 가장 중요한 목표입니다.
- 빠른 응답 속도: 짧은 트랜잭션을 실시간으로 처리해야 하므로 최적화된 성능이 요구됨
- 데이터 무결성 보장:
ACID속성을 준수하여 데이터 일관성을 유지 - 작은 트랜잭션 단위: 대부분
INSERT,UPDATE,DELETE연산으로 구성됨 - 동시성 제어: 여러 사용자가 동시에 데이터에 접근할 수 있도록 관리됨
- 정규화된 데이터 구조: 중복을 최소화하고 데이터 일관성을 보장하기 위해 스키마가 정규화됨
OLAP
OLAP(Online Analytical Processing)는 대량의 데이터를 다차원적으로 분석하여 비즈니스 의사결정을 지원하는 시스템입니다. 실시간 트랜잭션보다 데이터 분석에 초점을 맞추며, 데이터 웨어하우스 환경에서 주로 사용됩니다.
- 대량의 데이터 분석: 수년간 축적된 데이터를 대상으로 복잡한 쿼리 수행
- 고속 데이터 조회: 데이터를 사전 집계하여 빠르게 조회 가능
- 비정규화된 데이터 구조: 분석 속도를 높이기 위해 중복 데이터를 허용
- ETL 프로세스 활용: 데이터 웨어하우스로 데이터를 주기적으로 적재
MOLAP
MOLAP(Multidimensional OLAP)는 다차원 데이터베이스를 사용하여 데이터를 사전에 집계하고 저장하는 방식입니다. 분석에 필요한 데이터를 미리 계산하여 저장하므로 빠른 조회가 가능하지만, 저장 공간을 많이 차지하는 단점이 있습니다.
- 장점: 사전 집계된 데이터를 사용하므로 조회 속도가 매우 빠름
- 단점: 데이터가 많을수록 저장 공간이 급격히 증가하며, 실시간 데이터 반영이 어려울 수 있음
ROLAP
ROLAP(Relational OLAP)는 관계형 데이터베이스에서 SQL 기반으로 OLAP 연산을 수행하는 방식입니다. 대용량 데이터 분석에 적합하지만, 실시간 집계 연산을 수행해야 하므로 속도가 느릴 수 있습니다. 다양한 복잡한 쿼리 분석, 트랜잭션 데이터 활용 등에 적합합니다.
- 장점: 기존 RDBMS를 활용하므로 확장성이 뛰어나고, 대규모 데이터 처리에 적합함
- 단점: 매번 집계를 수행해야 하므로 조회 속도가 MOLAP보다 상대적으로 느림
HOLAP
HOLAP(Hybrid OLAP)는 MOLAP과 ROLAP의 장점을 결합한 방식으로, 자주 조회되는 데이터는 MOLAP 방식으로 사전 집계하여 저장하고, 나머지는 ROLAP 방식으로 처리하는 하이브리드 모델입니다. 대규모 데이터 분석과 빠른 응답 속도가 모두 필요한 경우에 적합합니다.
- 장점:
MOLAP의 빠른 조회 속도와ROLAP의 대용량 데이터 처리 능력을 동시에 활용 가능 - 단점: 구조가 복잡하고, 데이터의 저장 방식이 복합적이므로 관리 비용이 높음
Indexing
Indexing은 검색 성능을 최적화하기 위한 핵심 기법입니다. 인덱스를 사용하면 테이블 전체 스캔을 피하고, 보다 빠르게 원하는 데이터를 찾을 수 있습니다.
B-Tree
B-Tree는 데이터베이스에서 가장 많이 사용되는 전통적인 트리 기반 인덱스 구조로, Balanced Tree 형태를 유지하면서 검색 성능을 일정하게 보장하지만, 삽입 및 삭제 시 균형을 맞추는 과정에서 성능이 저하될 수 있습니다.
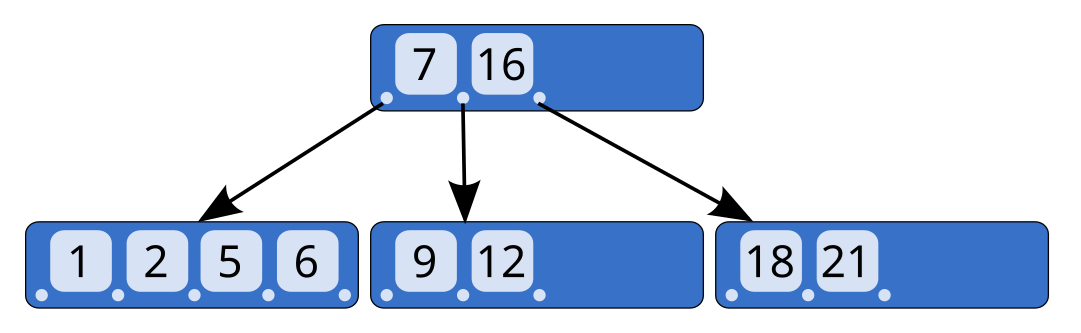
- 균형 트리 구조: 모든 리프 노드가 동일한 깊이를 유지하므로 검색 속도가 일정함
- 노드에 키와 데이터 저장: 각 노드가 키와 함께 데이터를 직접 저장하여 중간 노드에서도 데이터를 찾을 수 있음
- 이진 탐색 기반 검색: 각 노드에서 이진 탐색을 수행하여 키를 빠르게 찾음
- 삽입 및 삭제 시 균형 유지: 새로운 키가 삽입되거나 삭제될 때 자동으로 균형을 맞추므로 성능이 안정적임
B+Tree
B+Tree는 B-Tree를 확장하여 리프 노드에서만 데이터를 저장하는 구조로, 범위 검색 성능이 뛰어나지만, 중간 노드에는 키 값만 저장되므로 특정 키를 찾을 때 더 많은 단계를 거칠 수 있습니다.
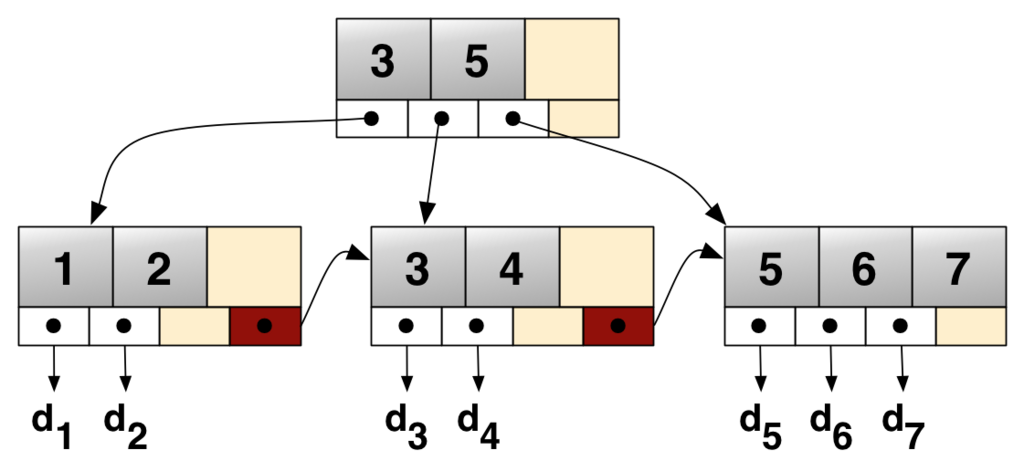
- B-Tree의 확장 버전: 내부 노드에는 키 값만 저장하고, 리프 노드에서만 데이터를 저장하여 검색 성능을 최적화함
- 순차 접근 최적화: 리프 노드들이
Linked List형태로 연결되어 있어 범위 검색이 빠름 - 디스크 I/O 감소: 많은 데이터를 저장할 수 있어 트리의 높이가 낮아지고, 검색 시 디스크 접근 횟수가 줄어듦
- 범위 검색과 정렬 최적화:
BETWEEN,ORDER BY,GROUP BY같은 연산에서 뛰어난 성능을 발휘함
Hash Index
Hash Index는 해시 함수를 사용하여 데이터를 빠르게 조회할 수 있지만, 순차 검색이나 범위 검색이 불가능하다는 단점이 있습니다.
- 빠른 키 검색: 특정 키 값을 조회할 때
O(1)의 시간 복잡도로 검색 가능 - 충돌 해결 필요: 같은 해시 값이 생성될 경우, 체이닝 또는 개방 주소법으로 충돌을 해결해야 함
- 순차 검색 비효율적: 해시 기반 구조이므로
BETWEEN연산 같은 범위 검색이 불가능함 - OLTP 환경에 적합: 빠른 단일 키 검색이 필요한
OLTP시스템에서 주로 사용됨