Sorting Data
정렬은 데이터 구조에서 중요한 연산 중 하나로, 데이터를 일정한 순서로 정리하는 과정입니다. 정렬 알고리즘은 효율성과 안정성에 따라 다양한 방식이 존재하며, 특정 상황에 따라 적절한 알고리즘을 선택하는 것이 중요합니다.
Comparison Sorting
원소 간 크기를 비교하여 정렬하는 방식으로, 데이터의 초기 정렬 상태에 따라 성능이 달라질 수 있으며, 입력 크기가 클수록 적절한 알고리즘 선택이 중요하다.
Merge Sort
Merge Sort은 분할 정복 기법을 사용하여 배열을 절반으로 나누고, 각각 정렬한 후 병합하는 방식이다. 항상 정렬된 상태를 유지하며 데이터를 합치기 때문에 안정 정렬에 속한다. 다만, 정렬 과정에서 추가적인 메모리 공간이 필요하다.
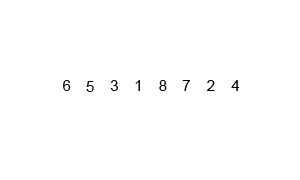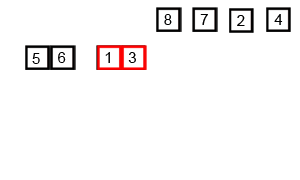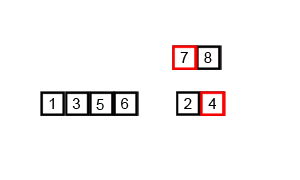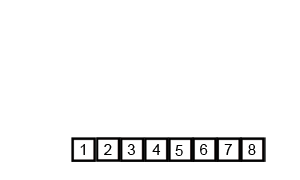
- 시간 복잡도
- 최악, 평균, 최선:
O(N log N) - 항상 일관된 성능을 보장하며, 데이터 정렬 상태에 영향을 받지 않는다.
- 최악, 평균, 최선:
import time
import random
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
arr = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
arr.append(left[i])
i += 1
else:
arr.append(right[j])
j += 1
arr.extend(left[i:])
arr.extend(right[j:])
return arr
if __name__ == "__main__":
start = time.time()
arr =[]
for _ in range(1000000):
arr.append(random.randint(1, 1000000))
arr = merge_sort(arr)
print("First 10 sorted elements:", arr[:10])
end = time.time()
print(f"Execution time: {end - start:.2f} seconds")
First 10 sorted elements: [1, 1, 1, 2, 2, 3, 3, 6, 6, 7]
Execution time: 2.19 seconds
Quick Sort
Quick Sort는 기준 값을 정하고, 이를 중심으로 작은 값과 큰 값으로 나눈 뒤 재귀적으로 정렬하는 방식이다. 제자리 정렬이 가능해 메모리 효율이 좋지만, 피벗 선택이 잘못되면 성능이 저하될 수 있다.
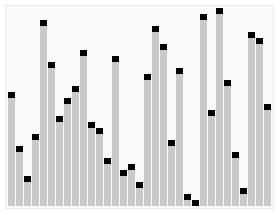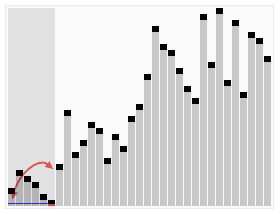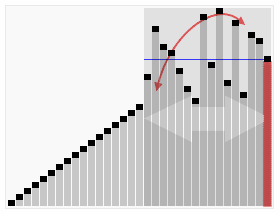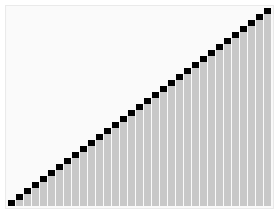
- 시간 복잡도
- 최선, 평균:
O(N log N) - 최악 (이미 정렬된 경우, Pivot이 최솟값 또는 최댓값일 때):
O(N^2)
- 최선, 평균:
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
First 10 sorted elements: [1, 1, 1, 2, 2, 3, 3, 6, 6, 7]
Execution time: 1.86 seconds
Heap Sort
Heap Sort는 힙 자료구조를 사용하여 최댓값 또는 최솟값을 반복적으로 추출하며 정렬하는 방식이다. 항상 일정한 성능을 보장하지만, 힙을 유지하는 과정에서 연산량이 많아 실제 실행 속도는 Quick Sort보다 느릴 수 있다.
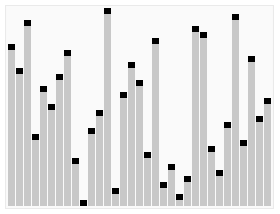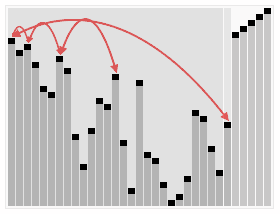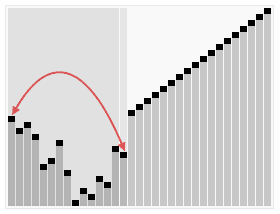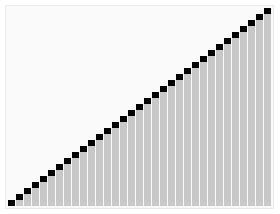
- 시간 복잡도
- 최악, 평균, 최선:
O(N log N)
- 최악, 평균, 최선:
def heapify(arr, n, i):
largest = i
left = 2 * i + 1
right = 2 * i + 2
if left < n and arr[left] > arr[largest]:
largest = left
if right < n and arr[right] > arr[largest]:
largest = right
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
def heap_sort(arr):
n = len(arr)
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i]
heapify(arr, i, 0)
First 10 sorted elements: [1, 1, 1, 2, 2, 3, 3, 6, 6, 7]
Execution time: 3.95 seconds
Non-comparison Sorting
원소 간 직접적인 비교 없이 정렬하는 방식으로, 숫자의 자릿값이나 빈도를 활용한다. 특정한 조건(예: 정수형 데이터, 제한된 범위의 값 등)에서만 사용할 수 있지만, 비교 기반 정렬보다 더 빠른 시간 복잡도를 가질 수 있다.
Counting Sort
Counting Sort는 숫자의 등장 횟수를 미리 계산하여 정렬하는 방식이다. 비교 연산을 사용하지 않아 빠르지만, 숫자의 범위가 클 경우 메모리 사용량이 증가할 수 있다.
- 시간 복잡도
- 최악, 평균, 최선:
O(N + K)(K는 숫자의 범위)
- 최악, 평균, 최선:
def counting_sort(arr):
max_value = max(arr)
count = [0] * (max_value + 1)
for num in arr:
count[num] += 1
arr = []
for i in range(len(count)):
arr.extend([i] * count[i])
return arr
First 10 sorted elements: [1, 2, 2, 3, 3, 4, 5, 6, 7, 7]
Execution time: 0.49 seconds
Radix Sort
Radix Sort는 숫자의 자릿수를 기준으로 여러 번 정렬하는 방식이다. 비교 연산 없이 빠르게 정렬할 수 있지만, 특정한 조건에서만 효율적이다.
- 시간 복잡도
- 최악, 평균, 최선:
O(N * K)(K는 자릿수)
- 최악, 평균, 최선:
def radix_sort(arr):
max_num = max(arr)
exp = 1
while max_num // exp > 0:
arr = radix_sort_by_digit(arr, exp)
exp *= 10
return arr
def radix_sort_by_digit(arr, exp):
count = [0] * 10
output = [0] * len(arr)
for num in arr:
index = (num // exp) % 10
count[index] += 1
for i in range(1, 10):
count[i] += count[i - 1]
for i in range(len(arr) - 1, -1, -1):
index = (arr[i] // exp) % 10
output[count[index] - 1] = arr[i]
count[index] -= 1
return output
First 10 sorted elements: [1, 2, 2, 3, 3, 4, 5, 6, 7, 7]
Execution time: 1.35 seconds