WebToon Grepp
2025.02 - 2025.03 | GitHub

개요
웹툰 시장은 급속도로 성장하고 있으며, 사용자들의 소비 패턴을 분석하는 것이 중요해지고 있습니다. 본 프로젝트는 네이버 및 카카오 웹툰 데이터를 크롤링하여 조회수, 댓글 수, 좋아요 수, 장르별 통계를 분석하는 데이터 파이프라인을 구축하는 것을 목표로 합니다. 이를 통해 사용자들에게 인사이트를 제공하고, 데이터 기반 의사 결정을 지원할 수 있도록 합니다.
역할
- V1 – Python 크롤러 개발을 통한 웹툰 데이터 자동 수집
- V2 – Spark 기반 ETL을 활용한 데이터 가공 자동화
- V3 – Airflow를 활용한 데이터 파이프라인 구축
- V4 – AWS 클라우드 인프라 환경 구성 및 운영 자동화
- V5 – Flask 웹 서비스 개발을 통한 사용자 인터페이스 구현
기술 스택
- Python, Flask, PostgreSQL
- Airflow, Spark, dbt
- AWS (EC2, S3, Redshift), Docker, GitHub Actions, Nginx, Gunicorn
데이터 파이프라인 자동화 및 운영 효율화
데이터 수집 및 변환 작업을 Airflow를 활용하여 파이프라인을 자동화하고, DAG(Directed Acyclic Graph) 기반으로 데이터 처리 흐름을 관리했습니다. 또한, Slack 알림 기능을 연동하여 실시간으로 DAG 상태를 모니터링할 수 있게 구성하였으며, 커스텀 Operator와 Hook을 직접 구현하여 다양한 형태의 작업을 유연하게 처리할 수 있도록 했습니다. 이로 인해 데이터 파이프라인의 안정성과 효율성이 크게 향상되었습니다.
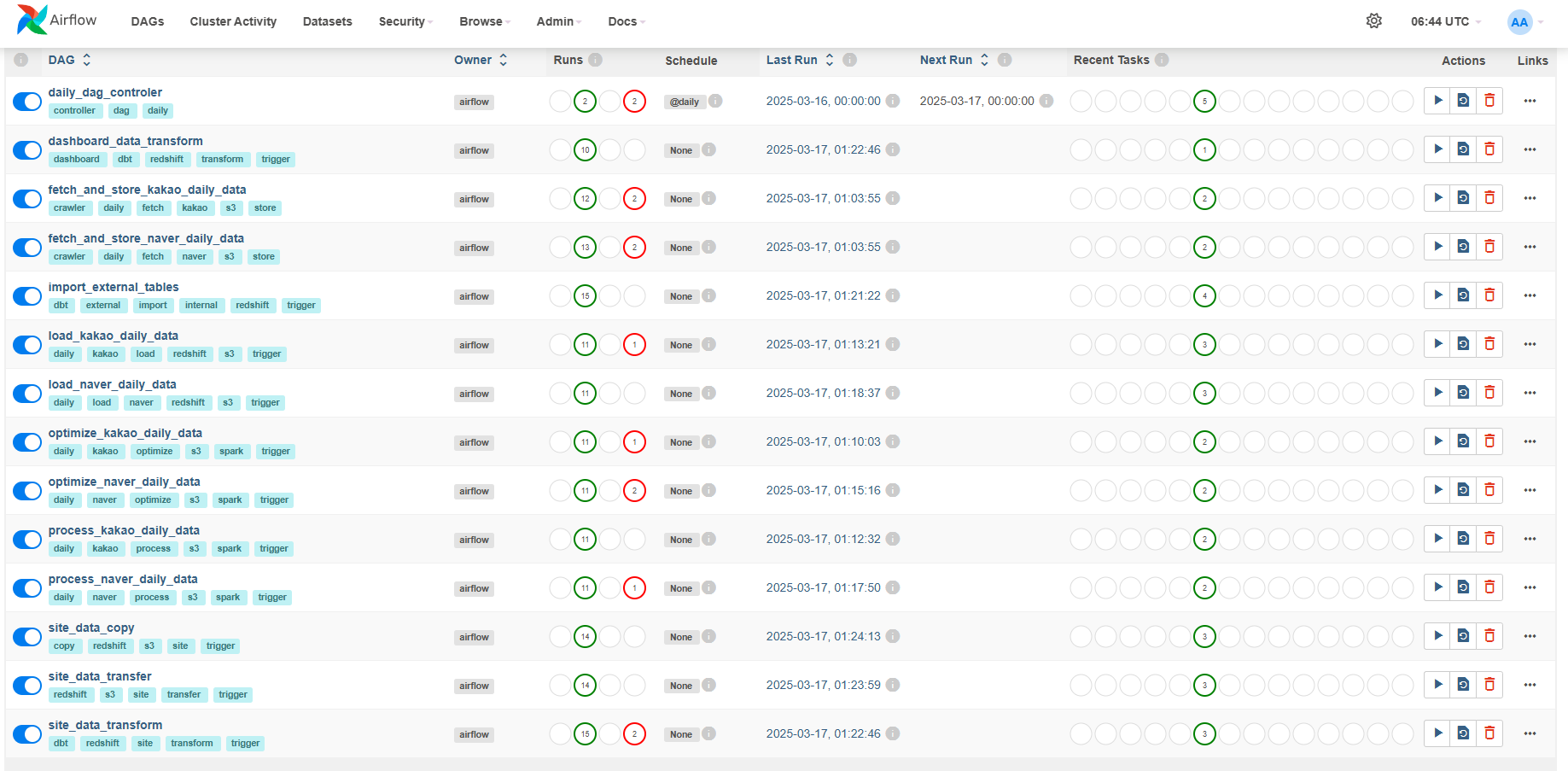
Airflow Pipeline
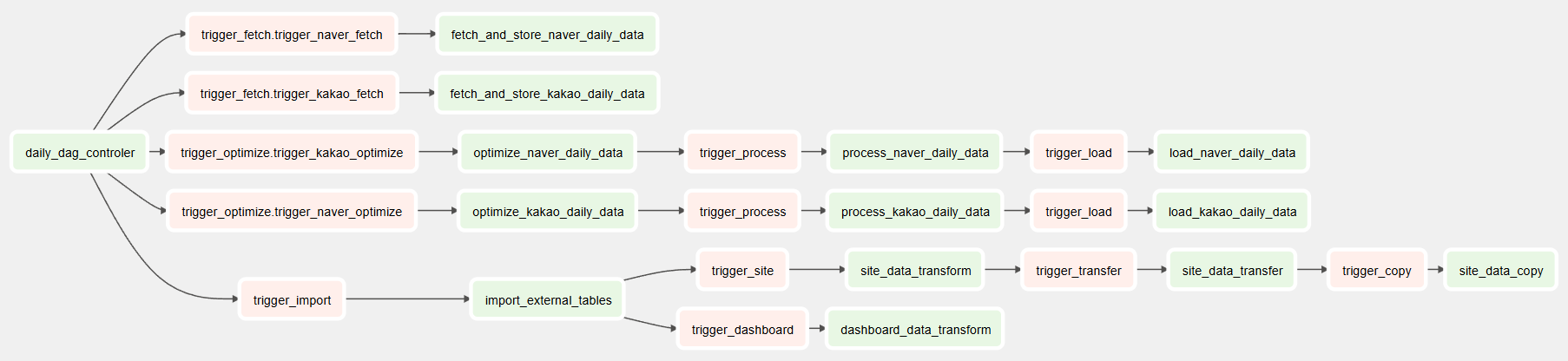
DAG Dependencies
웹툰 데이터 크롤링 시스템 개발
웹툰 데이터를 자동으로 수집하는 시스템을 구축하여, 웹툰 관련 정보를 효율적으로 처리하고 제공할 수 있는 기반을 마련했습니다. 이 시스템은 대규모 웹툰 데이터를 빠르고 안정적으로 크롤링할 수 있도록 설계되었습니다.
데이터 크롤링 속도 개선
기존 방식
단일 프로세스 환경에서 웹툰 데이터를 순차적으로 수집하는 방식으로, 데이터를 하나씩 처리하면서 수집 시간이 길어지고, 서버에 과도한 부하가 발생했습니다. 이러한 방식은 대규모 데이터를 처리하는 데 비효율적이며, 크롤링 속도가 매우 느려서 전체적인 데이터 수집에 시간이 많이 소요되었습니다.
개선된 방식
concurrent.futures를 활용해 멀티 스레딩 기반의 병렬 크롤링 환경을 구축하였고, 이를 통해 전체 크롤링 속도를 약 60% 개선했습니다. 병렬 처리를 통해 크롤링 효율성뿐만 아니라 안정성도 향상되었으며, 대규모 데이터를 빠르게 수집하고 저장할 수 있는 구조로 개선되었습니다.
대용량 ETL 처리 성능 개선
기존 방식
Pandas를 사용하여 데이터를 처리하는 방식은 주로 메모리 내에서 작업을 진행했기 때문에, 데이터의 양이 많아질수록 메모리 부족 현상이 발생하고 처리 속도가 저하되었습니다. 또한, 데이터 흐름의 확장성이 부족해 대규모 데이터를 처리하기 위한 최적화가 어려웠습니다.
개선된 방식
Spark 환경으로 전환하여 분산 처리 기반의 ETL 파이프라인을 구성했습니다. 데이터 흐름을 raw → optimized → processed 3단계로 구조화하여 각 단계별로 책임을 분리하였고, 이를 통해 메모리 부족 문제를 해결하고 처리 성능을 크게 향상시켰습니다.
AWS 기반 인프라 구축 및 배포 자동화
AWS 기반으로 클라우드 인프라를 구축하고, 이를 효율적으로 운영하기 위한 환경을 GitHub Actions와 AWS SSM을 연동하여 배포 시스템을 구축했습니다. 이를 통해 SSH 접속 없이 안전하고 효율적인 배포가 가능해졌습니다.
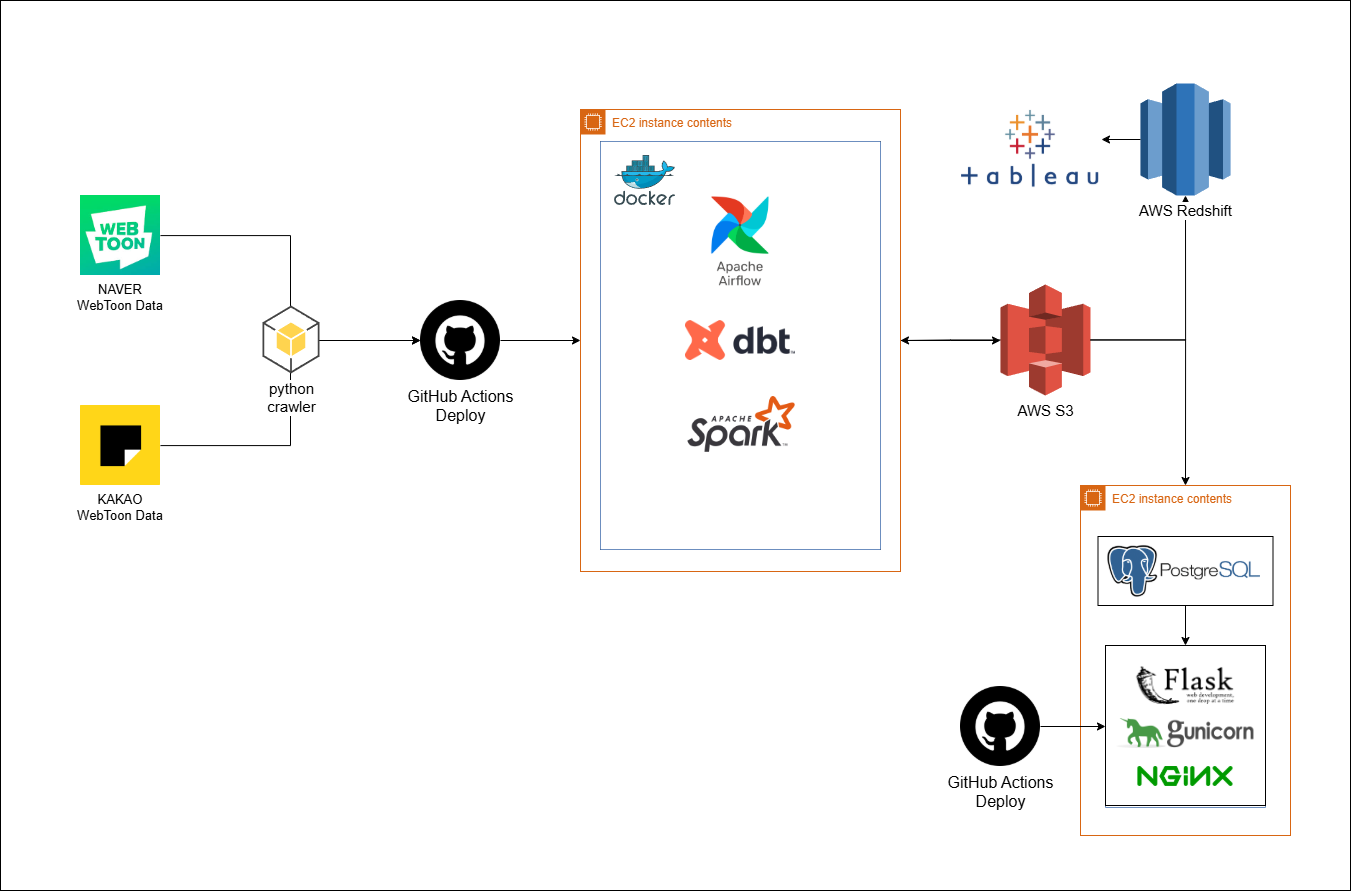
AWS Architecture
데이터 시각화 웹 서비스 구축
Flask를 이용해 웹 서비스를 구축하고, 프로덕션 DB와 연동하여 데이터 시각화를 제공하는 웹 인터페이스를 구현했습니다. 사용자 친화적인 UI를 통해 웹툰 데이터를 시각화하고 제공하는 시스템을 구현했습니다.
Web UI
회고
웹툰 데이터를 기반으로 사용자 소비 패턴과 인기 트렌드를 분석하며 추천 시스템과 콘텐츠 기획에 인사이트를 제공해볼 수 있었고, Spark를 활용해 대용량 데이터를 효율적으로 처리한 점도 의미 있었습니다. 댓글 분석의 부족, 플랫폼 다양성의 한계, 리소스 제약 등 아쉬운 부분도 있었지만, 데이터 기반 문제 해결 과정을 직접 경험해볼 수 있었던 좋은 경험이었습니다.