

이우람
데이터 중심의 자동화와 파이프라인 구축에 강점을 가진 개발자입니다
Python과 Shell을 활용한 업무 자동화와 워크플로우 최적화 경험과 Airflow를 이용해 안정적이며 확장 가능한 데이터 파이프라인을 구축해 왔습니다. 또한, CI/CD 자동화 설계와 AWS·GCP 클라우드 환경 운영 경험을 통해 서비스 안정성과 배포 효율성을 지속적으로 개선하고 있습니다.
웹 백엔드부터 다양한 내부 도구 개발까지 폭넓은 역량을 갖추고 있습니다
Flask와 Django를 이용한 REST API 설계 및 웹 백엔드 개발 경험은 물론, LangChain 기반 AI 서비스 개발과 PySide를 활용한 GUI 툴 제작에도 참여했습니다. 또한, PostgreSQL, MongoDB, 웹 크롤링을 통한 데이터 수집 및 실시간 처리 프로젝트를 수행하며 문제 해결 능력을 꾸준히 키워왔습니다.
Skills
- Languages: Python, Shell, JavaScript, C#
- Workflow Orchestration: Airflow, Jenkins, GitHub Actions, n8n
- Backend Development: Flask, Django, Gunicorn, NGINX
- Data Engineering: Spark, Kafka, dbt, PostgreSQL, MongoDB, Elasticsearch
- Cloud & Container: AWS, GCP, Docker, Docker Compose, Linux
- Tools & Libraries: Git, LangChain, scikit-learn, pytest, PySide
KBO 데이터 포털
2025.03 - present | GitHub

개요
KBO 리그는 팬들의 관심이 높아지는 스포츠 콘텐츠로, 팀과 선수 간 데이터를 분석하는 것이 중요해지고 있습니다. 본 프로젝트는 KBO 데이터를 크롤링하여 팀/선수의 기록을 수집·비교·분석하며 승부 예측까지 수행하는 데이터 파이프라인을 구축하는 것을 목표로 합니다. 이를 통해 팬들에게 인사이트를 제공하고, 데이터 기반 분석을 지원할 수 있도록 합니다.
역할
- V1 – Python 크롤러와 dbt를 활용한 데이터 수집 및 모델링 자동화
- V2 – Airflow와 GCP 기반 파이프라인 구성 및 GCS 연동 저장
- V3 – Flask 기반 웹 서비스 개발 및 Highcharts 시각화 제공
- V4 – Scikit-learn 기반 머신러닝 모델로 승부 예측 기능 구현
- V5 – GCE 기반 API 서버 구축 및 카카오 챗봇 연동 기능 제공
기술 스택
- Python, Flask, pytest, PostgreSQL
- Airflow, dbt, scikit-learn
- GCP (GCE, GCS, BigQuery), Docker, GitHub Actions
KBO 데이터 수집 및 분석 시스템 개발
KBO 리그 관련 데이터를 자동으로 수집하고 분석하는 시스템을 구축하여, 팀 및 선수 데이터를 효과적으로 처리하고 비교할 수 있는 기반을 마련했습니다. 이 시스템은 다양한 경기 정보와 통계를 빠르게 수집하고 활용할 수 있도록 설계되었습니다.
크롤링 로직 클래스화 및 구조 개선
기존 방식
기존에는 단일 스크립트 내에서 모든 데이터를 순차적으로 수집하는 방식으로, 기능 확장이 어렵고 관리가 복잡했습니다. 또한, 경기 일정, 팀, 선수 데이터를 하나의 흐름에서 처리하면서 유지보수가 비효율적이었습니다.
개선된 방식
경기 일정 및 결과, 선수 데이터를 클래스로 분리하고, 날짜별·선수별로 파티션 구조를 적용하여 데이터 처리의 확장성과 효율성을 향상시켰습니다. 이로 인해 데이터 수집 로직이 명확하게 구분되고, 재사용 및 추가 기능 개발이 쉬워졌습니다. 또한, 데이터 저장 구조가 명확해져 쿼리 성능도 개선되었습니다.
dbt 기반 ELT 모델링 개선
기존 방식
수집한 원시 데이터를 DB에 저장한 뒤, 분석용 테이블 생성을 위해 복잡한 SQL 쿼리를 직접 작성해 실행했습니다. 쿼리 재사용이나 관리가 어려워 유지보수가 번거로웠고, 반복적인 수작업이 많아 데이터 파이프라인 관리에 시간이 많이 소요되었습니다.
개선된 방식
dbt를 도입하여 ELT 프로세스를 표준화했습니다. 모델 단위의 SQL 관리와 버전 관리가 가능해졌고, 자동 문서화 및 테스트 기능을 통해 신뢰도 높은 데이터 모델링이 가능해졌습니다. 또한, Airflow와 연계해 dbt 모델을 주기적으로 실행함으로써, 최신 데이터를 자동 반영하는 구조로 개선했습니다.
크롤링 로직 검증 및 테스트 자동화
데이터 수집 과정의 안정성과 정확성을 높이기 위해, 크롤링 로직의 정상 동작 여부를 확인하고 수집된 데이터가 기존 포맷과 일치하는지를 검증하는 pytest 기반 테스트 스크립트를 추가했습니다. 또한, GitHub Actions와 연동하여 코드가 push될 때마다 자동으로 테스트가 실행되도록 구성함으로써, 문제를 조기에 감지하고 안정적인 데이터 파이프라인 운영을 가능하게 했습니다.
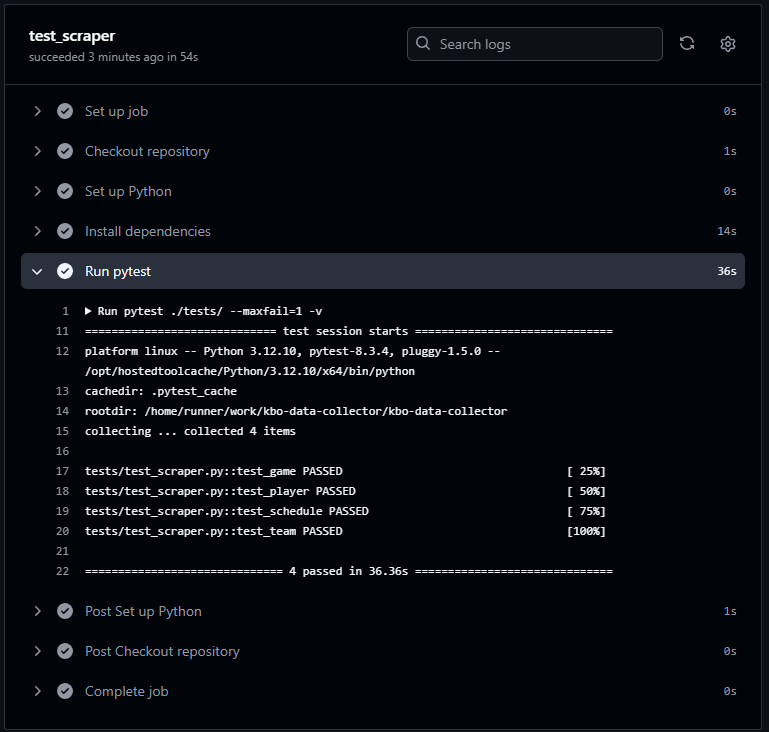
Test Scraper
머신러닝 기반 KBO 경기 승부 예측
Scikit-learn 기반의 머신러닝 모델을 활용해 KBO 경기의 승부를 예측하는 기능을 구현했습니다. 크롤링한 과거 경기 데이터를 기반으로 경기 일자, 시즌 및 최근 팀 성적 등의 주요 피처를 선별하였으며, LightGBM 모델을 사용하여 승패를 예측합니다. 이 과정에서 데이터 전처리, 학습/테스트 분리, 모델 성능 평가를 수행하였고, 예측 결과를 시각화하여 모델 신뢰도를 분석할 수 있도록 구성했습니다. (F1-score 약 65.9%, AUC 약 77.0%)
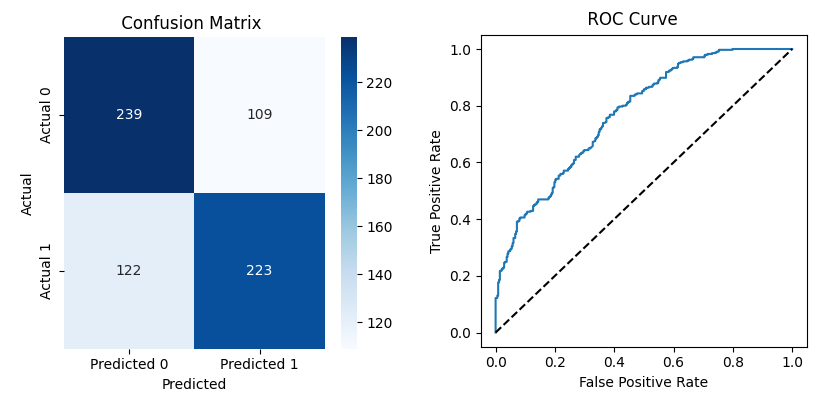
Metrics
KBO 경기 일정 및 승부 예측 챗봇 서비스 구현
Flask 기반의 API 서버를 구축하고, 이를 카카오 챗봇과 연동하여 KBO 경기 일정 조회 및 승부 예측 기능을 제공하는 서비스를 구현했습니다. 사용자는 카카오톡 챗봇을 통해 오늘의 경기 일정이나 특정 팀의 향후 일정을 조회할 수 있으며, Flask 서버에서 머신러닝 모델을 통해 예측된 승패 결과도 함께 제공합니다.
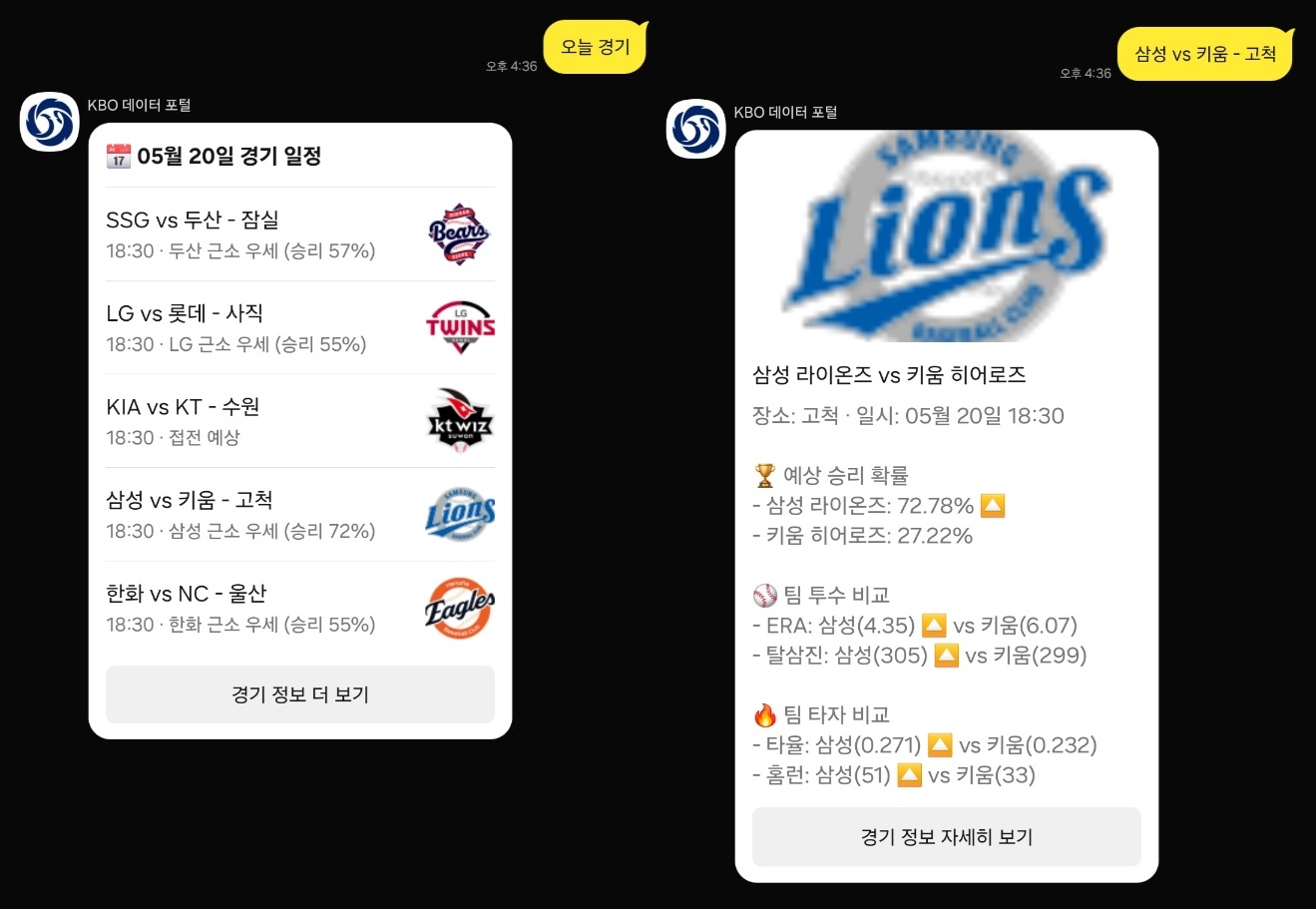
ChatBot
데이터 시각화 웹 서비스 구축
Flask 프레임워크를 활용해 웹 기반 시각화 서비스를 구축했습니다. 크롤링한 KBO 데이터를 사용자에게 제공하기 위한 웹 인터페이스를 구성하였으며, KBO 공식 홈페이지와 유사한 UI 디자인을 적용하여 익숙하고 직관적인 사용자 경험을 제공합니다. 이를 통해 웹사이트 방문자는 원하는 팀이나 선수 데이터를 손쉽게 탐색하고 접근할 수 있습니다.
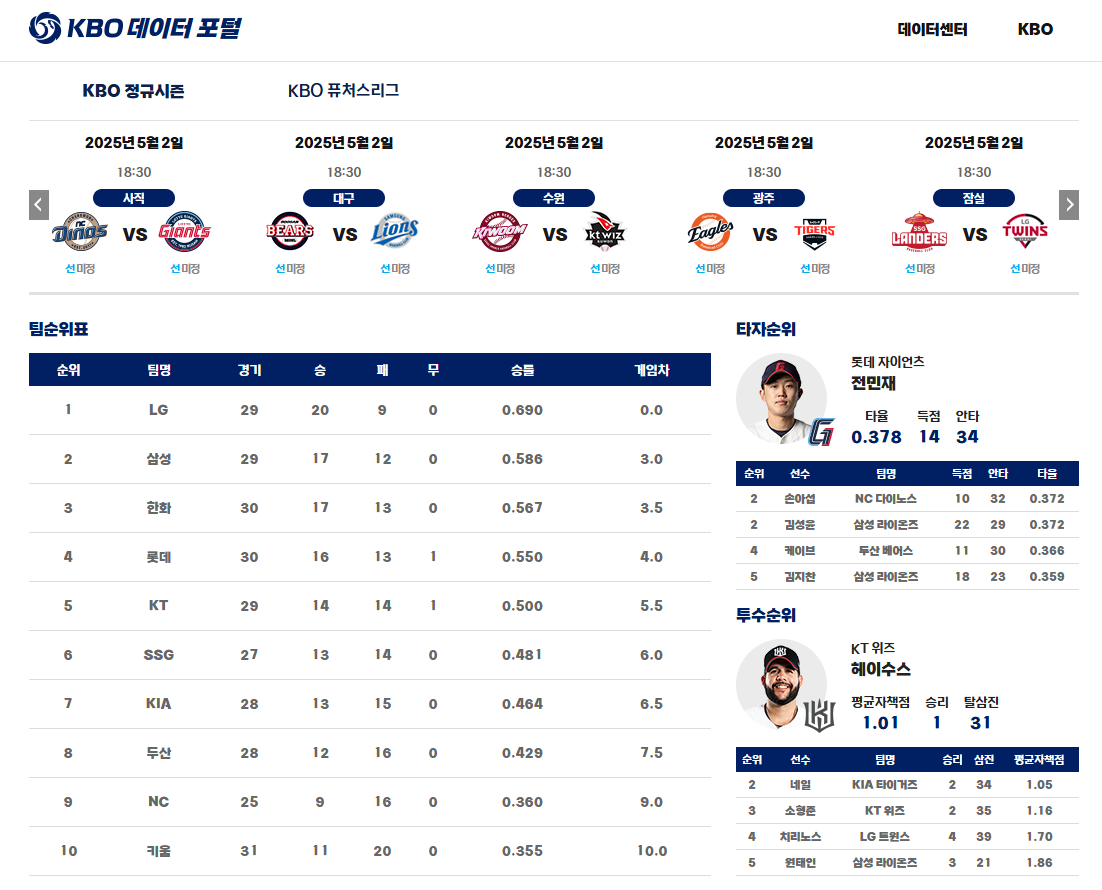
Web UI
Highcharts 기반 비교 분석 차트 시각화
데이터 시각화는 Highcharts 라이브러리를 활용하여 구현했으며, 이를 통해 팀 및 선수 간의 통계 비교, 시즌별 추이 시각화, 주요 지표 분석을 제공합니다. 사용자는 동적인 그래프를 통해 여러 팀의 경기력을 비교하거나 특정 선수의 성과를 시각적으로 확인할 수 있으며, 이를 통해 KBO 데이터를 보다 심층적으로 해석할 수 있는 기반을 마련했습니다.

Chart
회고
KBO 데이터를 자동으로 수집하고 분석하는 시스템을 구축하면서, Airflow와 Flask를 활용해 데이터 파이프라인과 시각화 기능을 성공적으로 구현했습니다. dbt를 도입해 데이터 모델링이 훨씬 간편해졌고, 나아가 머신러닝 기반의 승부 예측 기능까지 완성하여 LightGBM 모델을 활용한 경기 결과 예측도 가능합니다. 또한, 예측 결과를 카카오 챗봇과 연동하여 사용자와의 실시간 인터페이스를 구축하는 데에도 성공했습니다. 프로젝트를 통해 자동화, 데이터 처리 효율성, 실시간 사용자 서비스 제공 측면에서 큰 발전을 이루었고, 이 경험을 바탕으로 지속적인 개선을 이어가고 있습니다.
Others Projects
-
PRMate
2025.07 - present | GitHub | Marketplace GitHub Pull Request 자동 코드 리뷰 AI 도구 개발 주요 역할: LangChain 기반 LLM 코드 리뷰 시스템 개발 , GitHub Actions 자동화 워크플로우 구축 백엔드 API 및 프롬프트 설계, CI/CD 파이프라인 구성 등 코드 리뷰 프로세스 전반을 직접 개발 -
AutoLottery
2025.07 - 2025.07 | GitHub 동행복권 6/45 로또 자동 구매 데스크탑 애플리케이션 주요 역할: PySide 기반 사용자 인터페이스 설계 및 로또 자동 구매 알고리즘 개발 안정적인 실행을 위한 에러 핸들링과 성능 최적화, 사용자 편의성을 고려한 UI/UX 개선 작업 수행 -
WebToon Grepp
2025.02 - 2025.03 | GitHub 웹툰 플랫폼 데이터를 크롤링하고 시각화하는 통계 분석 웹 애플리케이션 주요 역할: 웹툰 정보 크롤링 로직 개발, Flask 기반 웹 서비스 구현 EC2·S3 중심의 AWS 인프라 구성 및 운영, 반응형 UI 설계 및 사용자 중심 인터페이스 구축 -
Exchangify
2025.01 - 2025.01 | GitHub 한국수출입은행 환율 데이터를 기반으로 한 환율 조회 및 비교 웹 서비스 주요 역할: 공공 API 데이터 수집, Django 기반 풀스택 개발, Chart.js를 활용한 시각화 기능 구현 API 설계부터 디자인까지 전반을 직접 개발하여 환율 변동을 직관적으로 확인할 수 있는 서비스 구축
Others
Certifications
-
정보처리산업기사
2020.12 | 한국산업인력공단
Awards
-
데이터 엔지니어링 데브코스 - 우수 프로젝트
2025.03 | ㈜그렙
정보처리산업기사
-
데이터 엔지니어링 데브코스 - 우수 프로젝트
2025.03 | ㈜그렙